

Modern businesses have data at their core, and this data is changing continuously. How can we harness this torrent of information in real-time? The answer is stream processing, and the technology that has since become the core platform for streaming data is Apache Kafka. Among the thousands of companies that use Kafka to transform and reshape their industries are the likes of Netflix, Uber, PayPal, and AirBnB, but also established players such as Goldman Sachs, Cisco, and Oracle.
Unfortunately, today’s common architectures for real-time data processing at scale suffer from undue complexity: there are many technologies that need to be stitched and operated together, and each individual technology is often complex by itself. This has led to a strong discrepancy between how we, as engineers, would like to work in an ideal world vs. how we actually end up working in practice.
When we set out to design the stream processing API for Apache Kafka – the Kafka Streams API – a key motivation has been to rethink the solution space for stream processing. Here, our vision has been to move stream processing out of the big data niche and make it available as a mainstream application development model. For us, the key to executing this vision has been to radically simplify how users can process data at any scale – from small to medium and to very large use cases. And in fact, one of our mantras is that, as application developers, we want to “Build Applications, Not Infrastructure!”
Let us pick a common use case example and use it to juxtapose how you’d implement such a use case with previous technologies in the stream processing space and how you’d do so with Apache Kafka and its Streams API. Imagine our task were to, say, build a fraud detection application. Essentially what we would need to do here is rather simple. The input to our application would consist of two main sources:
1. A real-time stream of customer transactions.
2. A continuously updated table of “context” per customer, such as each customer’s payment history. Oftentimes the input data for keeping this table up-to-date is also being made available through Kafka.
Our application would join the information in the input stream and the input table and then make an informed decision whether a new customer transaction in the input stream should be flagged as fraudulent or not. For example, if the customer has never made a payment outside the EU, then suddenly seeing a payment for this customer that originated in Australia would be very suspicious and most probably indicate fraudulent activity.
Before the introduction of Kafka’s Streams API, a common architecture for the use case above would look somewhat like this: (1) to collect and store customer transactions as a real-time stream you’d use Kafka as the de-facto standard, (2) to process the input stream you’d deploy a (typically shared) cluster of one of the stream processing frameworks such as Apache Spark or Apache Storm, into which you’d submit a framework-specific “processing job” for your fraud detection use case, and (3) to maintain a table for looking up the latest customer payment histories you’d use a (typically shared) external database cluster such as Cassandra. Given this architecture, you’d implement a “processing job” that is specific to the stream processing framework that you picked, and then submit your job to the shared processing cluster. This job would read the stream of customer transactions from Kafka and, for each incoming customer transaction, perform a DB lookup over the network to the shared database cluster, and then make the decision “is this transaction fraudulent or not?”.
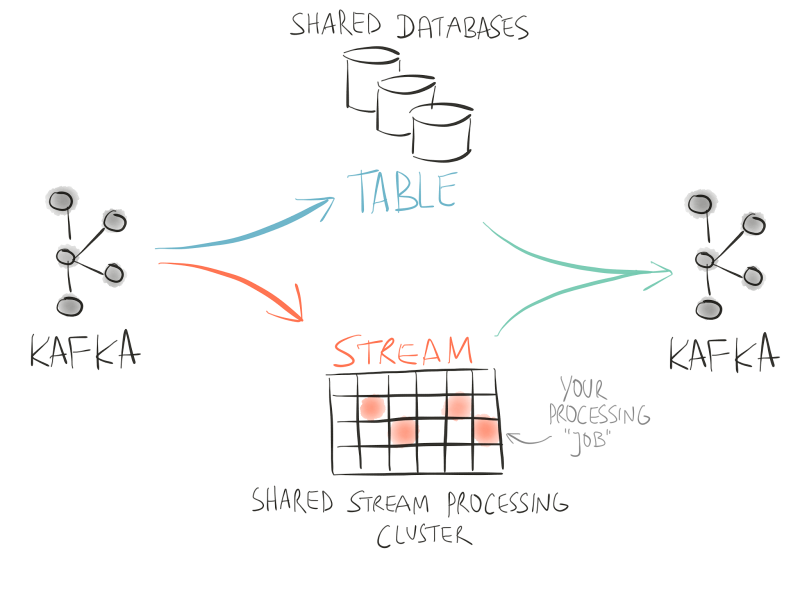
Figure 1: Example architecture for fraud detection without Kafka’s Streams API, where you need separate shared infrastructure for processing streams and tables.
Let’s take a step back here and ask ourselves: what are the upsides and downsides of this approach? At first sight, this architecture seems to satisfy our needs because we have covered all the essential requirements of our use case, haven’t we? However, there are actually a number of downsides to this approach, which I only briefly summarize here: (a) we are being forced to leverage three different pieces of technology in our architecture, even though use case seems to be rather simple (to join a stream and a table in order to make a decision based on the joined data); (b) the end-to-end SLA -- availability, latency, etc. -- of our use case depends on the combined SLAs of three different systems; (c) it is rather difficult for us when, moving forward, our business requirements change because we are required to carefully orchestrate how to change this rather complex architecture (e.g. when we need to upgrade the database); (d) also, when the processing cluster and/or the database cluster are being shared across teams in a company, everyone must co-exist peacefully in these shared environments so as not to step on each others’ toes. Also, we realize that we haven’t built a single, self-contained “fraud detection application” -- rather, it has been split and spread in small pieces across this architecture, some of which is run inside the processing cluster, some of which is in the database, and so on. So we must deal with (e) a significantly more challenging situation for operations and debugging. If, for example, there’s a sudden surge of end-to-end processing latency -- think: customer transactions suddenly take much longer to be fully processed -- where should we look? Did we make a mistake in our processing job? Did another team’s processing job impact ours? Were there network issues that impacted our processing job talking to our remote database, and so on. And finally, we realize that (f) developing and testing all this is rather difficult and time-consuming for us because, for instance, how would we replicate our production environment on our local development machines in an easy way?
As mentioned in the very beginning of this article, the Apache Kafka community felt that there should be a better way for implementing use cases such as the fraud detection example above. A stream processing technology should be part of the solution, and not become part of the problem you are struggling to solve. In comparison to all the existing stream processing technologies out there, Kafka’s Streams API opts for something very unique: it provides you with a Java library that you can use in standard Java or Scala applications (rather than framework-specific “jobs” that you submit to a processing cluster). And, by building on top of the rock-solid Kafka foundation, the Streams API “enriches” your applications so that they become elastic, highly scalable, fault-tolerant, stateful (if needed), and distributed. For example, you can containerize your application with Docker and then deploy your application with Kubernetes in the cloud or on-premises. Also, if you need to scale out your application (e.g. you need more computing capacity to process an increasing volume of incoming data), you simply start additional containers. If we need to scale down, we stop a few containers. All this can be done during live operations without causing downtime. This is very important because, in many cases, Kafka users are powering mission-critical products and services with their applications: here, you don’t want to take down your business because your stream processing technologies requires you to fully stop and restart your processing jobs in order to add or remove capacity. (Imagine a car mechanic told you to hold your breath until your car’s engine has been fixed.)
Going back to our fraud detection example, what would this use case look like when implemented with Kafka’s Streams API? We only need one piece of technology, and that is Apache Kafka. We can build a single, self-contained application that implements the use case end-to-end. The Kafka Streams API ships with first-class support for the two core abstractions that you need for stream processing: streams and tables. And as it turns out, there is a close relationship between streams and tables, which we call the stream-table duality. Our application reads incoming customer transactions into a so-called KStream, and it maintains a continuously updated table of customer payment histories via a KTable.
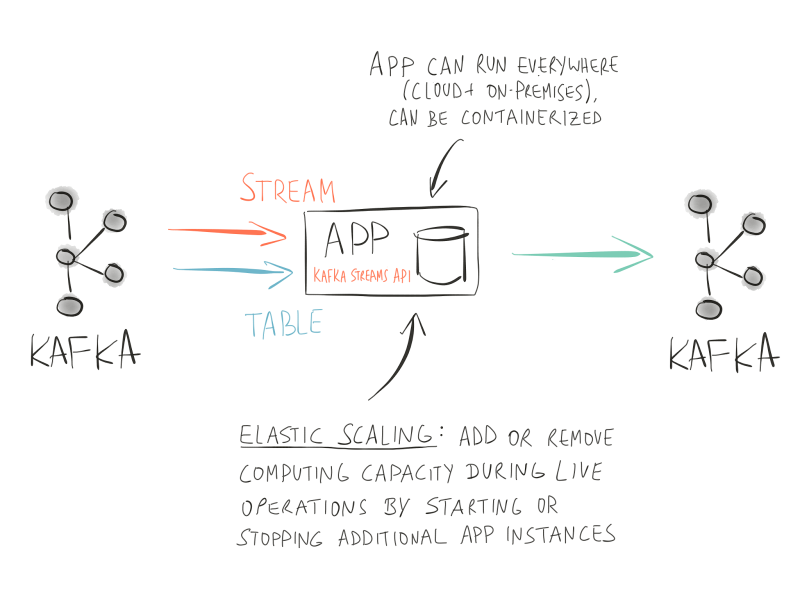
Figure 2: Example architecture for fraud detection with Kafka’s Streams API. You have now a self-contained fraud detection application that is a standard Java or Scala application, and you no longer need additional infrastructure. Thanks to the Kafka Streams API, your application can process both streams and tables easily for operations such as joins, aggregations, and windowing. Also, the application is fully fault-tolerant to prevent data loss and is also elastically scalable to process millions of customer transactions per second.
Joining the KStream and the KTable works on locally available data, thus eliminating the need for remote DB lookups over the network plus, ultimately in this use case, the need for the external database altogether. Likewise, we no longer need a separate processing cluster, because our application is fully scalable and elastic and is capable of processing millions of customer transactions per second. Everything that our application requires for its functioning is now fully under its own, exclusive control. This means we have addressed the downsides of (a) having to stitch together many different technologies, (b) ending up with a lower end-to-end SLA as a result of having to combine the respective SLAs of these different technologies, (c) high friction when needing to change or adapt our architecture, and (d) the intertwining of different teams, roadmaps, and priorities across the organization above. Also, we can now develop, test, and deploy our application much more easily, thereby also addressing the aforementioned (e) difficulties for operations and debugging and (f) challenges to achieve quick development and testing cycles. For instance, going back to our example of using Docker or a similar container technology, we can spin up development and test environments in a matter of seconds. If you want to try this out for yourself, I have recently blogged about the Confluent Kafka Music demo application, which demonstrates this with Docker and Confluent Docker images for Kafka.
If you have read up to this point, then you certainly have quite a few questions. If we can believe the above is true, how does all of this work? How can we build “normal” applications and still perform event-time processing with joins, aggregations, windowing, transparently handle late-arriving data, and much more? So, if I sparked your interest, then I’d invite you to join my Berlin Buzzwords talk Rethinking Stream Processing with Apache Kafka: Applications vs. Clusters, Streams vs. Databases on June 13, 2017 at 11:50 in room “Maschinenhaus”.
Also, if you want to learn more about Kafka’s Streams API, I’d recommend to read the Confluent Kafka Streams API documentation as well as the Kafka Streams API documentation on the Apache Kafka website. If you want to give it a try yourself, take a look at our Kafka Streams examples and demo applications, and notably our Docker-based Kafka Streams tutorial. And download Confluent Open Source.
About the author:
 Michael Noll is a product manager at Confluent, the company founded by the creators of Apache Kafka. Previously Michael was the technical lead of the Big Data platform of .COM/.NET DNS operator Verisign, where he grew the Hadoop, Kafka, and Storm based infrastructure from zero to petabyte-sized production clusters spanning multiple data centers – one of the largest Big Data infrastructures operated from Europe at the time. He is a known tech blogger in the Big Data community (www.michael-noll.com) and serves as a technical reviewer for publishers such as Manning in his spare time. Michael has a Ph.D. in computer science and is an experienced speaker, having presented at international conferences such as ACM SIGIR, Web Science, and ApacheCon.
Michael Noll is a product manager at Confluent, the company founded by the creators of Apache Kafka. Previously Michael was the technical lead of the Big Data platform of .COM/.NET DNS operator Verisign, where he grew the Hadoop, Kafka, and Storm based infrastructure from zero to petabyte-sized production clusters spanning multiple data centers – one of the largest Big Data infrastructures operated from Europe at the time. He is a known tech blogger in the Big Data community (www.michael-noll.com) and serves as a technical reviewer for publishers such as Manning in his spare time. Michael has a Ph.D. in computer science and is an experienced speaker, having presented at international conferences such as ACM SIGIR, Web Science, and ApacheCon.
